Simon Josefsson: Towards reproducible minimal source code tarballs? On *-src.tar.gz
While the work to analyze the xz backdoor is in progress, several ideas have been suggested to improve the software supply chain ecosystem. Some of those ideas are good, some of the ideas are at best irrelevant and harmless, and some suggestions are plain bad. I d like to attempt to formalize two ideas, which have been discussed before, but the context in which they can be appreciated have not been as clear as it is today.
- Reproducible tarballs. The idea is that published source tarballs should be possible to reproduce independently somehow, and that this should be continuously tested and verified preferrably as part of the upstream project continuous integration system (e.g., GitHub action or GitLab pipeline). While nominally this looks easy to achieve, there are some complex matters in this, for example: what timestamps to use for files in the tarball? I ve brought up this aspect before.
- Minimal source tarballs without generated vendor files. Most GNU Autoconf/Automake-based tarballs pre-generated files which are important for bootstrapping on exotic systems that does not have the required dependencies. For the bootstrapping story to succeed, this approach is important to support. However it has become clear that this practice raise significant costs and risks. Most modern GNU/Linux distributions have all the required dependencies and actually prefers to re-build everything from source code. These pre-generated extra files introduce uncertainty to that process.
*-src.tar.gz with at least the following properties:
- The tarball should allow users to build the project, which is the entire purpose of all this. This means that at least all source code for the project has to be included.
- The tarballs should be signed, for example with PGP or minisign.
- The tarball should be possible to reproduce bit-by-bit by a third party using upstream s version controlled sources and a pointer to which revision was used (e.g., git tag or git commit).
- The tarball should not require an Internet connection to download things.
- Corollary: every external dependency either has to be explicitly documented as such (e.g., gcc and GnuTLS), or included in the tarball.
- Observation: This means including all
*.pogettext translations which are normally downloaded when building from version controlled sources.
- The tarball should contain everything required to build the project from source using as much externally released versioned tooling as possible. This is the minimal property lacking today.
- Corollary: This means including a vendored copy of OpenSSL or libz is not acceptable: link to them as external projects.
- Open question: How about non-released external tooling such as gnulib or autoconf archive macros? This is a bit more delicate: most distributions either just package one current version of gnulib or autoconf archive, not previous versions. While this could change, and distributions could package the gnulib git repository (up to some current version) and the autoconf archive git repository and packages were set up to extract the version they need (gnulib s ./bootstrap already supports this via the gnulib-refdir parameter), this is not normally in place.
- Suggested Corollary: The tarball should contain content from git submodule s such as gnulib and the necessary Autoconf archive M4 macros required by the project.
- Similar to how the GNU project specify the ./configure interface we need a documented interface for how to bootstrap the project. I suggest to use the already well established idiom of running
./bootstrapto set up the package to later be able to be built via./configure. Of course, some projects are not using the autotool./configureinterface and will not follow this aspect either, but like most build systems that compete with autotools have instructions on how to build the project, they should document similar interfaces for bootstrapping the source tarball to allow building.
make dist that generate today s foo-1.2.3.tar.gz files.
I think one common argument against this approach will be: Why bother with all that, and just use git-archive outputs? Or avoid the entire tarball approach and move directly towards version controlled check outs and referring to upstream releases as git URL and commit tag or id. One problem with this is that SHA-1 is broken, so placing trust in a SHA-1 identifier is simply not secure. Another counter-argument is that this optimize for packagers benefits at the cost of upstream maintainers: most upstream maintainers do not want to store gettext *.po translations in their source code repository. A compromise between the needs of maintainers and packagers is useful, so this *-src.tar.gz tarball approach is the indirection we need to solve that. Update: In my experiment with source-only tarballs for Libntlm I actually did use git-archive output.
What do you think?
 I attended several sessions related to authentication topics. I discovered the keycloak software, which looks very
promising. I also attended an Oauth2 session which I had a hard time following, because I clearly missed some additional
knowledge about how Oauth2 works internally.
I also attended a couple of sessions that ended up being a vendor sales talk.
See also:
I attended several sessions related to authentication topics. I discovered the keycloak software, which looks very
promising. I also attended an Oauth2 session which I had a hard time following, because I clearly missed some additional
knowledge about how Oauth2 works internally.
I also attended a couple of sessions that ended up being a vendor sales talk.
See also:
 I very recently missed some semantics for limiting the number of open connections per namespace, see
I very recently missed some semantics for limiting the number of open connections per namespace, see 
 Our retiring room at the Old Delhi Railway Station.
Our retiring room at the Old Delhi Railway Station.
 Security outside the Taj Mahal complex.
Security outside the Taj Mahal complex.
 This red colored building is entrance to where you can see the Taj Mahal.
This red colored building is entrance to where you can see the Taj Mahal.
 Taj Mahal.
Taj Mahal.
 Shoe covers for going inside the mausoleum.
Shoe covers for going inside the mausoleum.
 Taj Mahal from side angle.
Taj Mahal from side angle.
 syncoid to TrueNAS In my homelab, I have 2 NAS systems:
Linux (Debian) TrueNAS Core (based on FreeBSD) On my Linux box, I use Jim Salter s sanoid to periodically take snapshots of my ZFS pool. I also want to have a proper backup of the whole pool, so I use syncoid to transfer those snapshots to another machine. Sanoid itself is responsible only for taking new snapshots and pruning old ones you no longer care about.
syncoid to TrueNAS In my homelab, I have 2 NAS systems:
Linux (Debian) TrueNAS Core (based on FreeBSD) On my Linux box, I use Jim Salter s sanoid to periodically take snapshots of my ZFS pool. I also want to have a proper backup of the whole pool, so I use syncoid to transfer those snapshots to another machine. Sanoid itself is responsible only for taking new snapshots and pruning old ones you no longer care about.

 Thanks to All Saints Day, I ve just had a 5 days weekend. One of those
days I woke up and decided I absolutely needed a cartonnage box for the
cardboard and linocut
Thanks to All Saints Day, I ve just had a 5 days weekend. One of those
days I woke up and decided I absolutely needed a cartonnage box for the
cardboard and linocut  One of the boxes was temporarily used for the plastic piecepack I got
with the
One of the boxes was temporarily used for the plastic piecepack I got
with the  One of the most common fallacies programmers fall into is that we will jump
to automating a solution before we stop and figure out how much time it would even save.
In taking a slow improvement route to solve this problem for myself,
I ve managed not to invest too much time
One of the most common fallacies programmers fall into is that we will jump
to automating a solution before we stop and figure out how much time it would even save.
In taking a slow improvement route to solve this problem for myself,
I ve managed not to invest too much time This article is cross-posting from grow-your-ideas. This is just an idea.
This article is cross-posting from grow-your-ideas. This is just an idea.

 The Amazon Kids parental controls are extremely insufficient, and I strongly advise against getting any of the Amazon Kids series.
The initial permise (and some older reviews) look okay: you can set some time limits, and you can disable anything that requires buying.
With the hardware you get one year of the Amazon Kids+ subscription, which includes a lot of interesting content such as books and audio,
but also some apps. This seemed attractive: some learning apps, some decent games.
Sometimes there seems to be a special Amazon Kids+ edition , supposedly one that has advertisements reduced/removed and no purchasing.
However, there are so many things just wrong in Amazon Kids:
The Amazon Kids parental controls are extremely insufficient, and I strongly advise against getting any of the Amazon Kids series.
The initial permise (and some older reviews) look okay: you can set some time limits, and you can disable anything that requires buying.
With the hardware you get one year of the Amazon Kids+ subscription, which includes a lot of interesting content such as books and audio,
but also some apps. This seemed attractive: some learning apps, some decent games.
Sometimes there seems to be a special Amazon Kids+ edition , supposedly one that has advertisements reduced/removed and no purchasing.
However, there are so many things just wrong in Amazon Kids:
 A welcome sign at Bangkok's Suvarnabhumi airport.
A welcome sign at Bangkok's Suvarnabhumi airport.
 Bus from Suvarnabhumi Airport to Jomtien Beach in Pattaya.
Bus from Suvarnabhumi Airport to Jomtien Beach in Pattaya.
 Road near Jomtien beach in Pattaya
Road near Jomtien beach in Pattaya
 Photo of a songthaew in Pattaya. There are shared songthaews which run along Jomtien Second road and takes 10 bath to anywhere on the route.
Photo of a songthaew in Pattaya. There are shared songthaews which run along Jomtien Second road and takes 10 bath to anywhere on the route.
 Jomtien Beach in Pattaya.
Jomtien Beach in Pattaya.
 A welcome sign at Pattaya Floating market.
A welcome sign at Pattaya Floating market.
 This Korean Vegetasty noodles pack was yummy and was available at many 7-Eleven stores.
This Korean Vegetasty noodles pack was yummy and was available at many 7-Eleven stores.
 Wat Arun temple stamps your hand upon entry
Wat Arun temple stamps your hand upon entry
 Wat Arun temple
Wat Arun temple
 Khao San Road
Khao San Road
 A food stall at Khao San Road
A food stall at Khao San Road
 Chao Phraya Express Boat
Chao Phraya Express Boat
 Banana with yellow flesh
Banana with yellow flesh
 Fruits at a stall in Bangkok
Fruits at a stall in Bangkok
 Trimmed pineapples from Thailand.
Trimmed pineapples from Thailand.
 Corn in Bangkok.
Corn in Bangkok.
 A board showing coffee menu at a 7-Eleven store along with rates in Pattaya.
A board showing coffee menu at a 7-Eleven store along with rates in Pattaya.
 In this section of 7-Eleven, you can buy a premix coffee and mix it with hot water provided at the store to prepare.
In this section of 7-Eleven, you can buy a premix coffee and mix it with hot water provided at the store to prepare.
 Red wine being served in Air India
Red wine being served in Air India
 Debian is running a "
Debian is running a "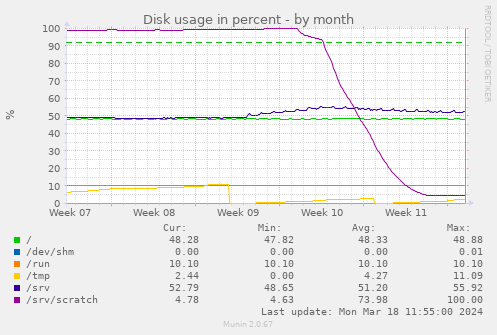 The initial dip from 100% to 95% is my first "what happens if we block repos
> 500 MB" attempt. Over the week after that, the git filter clones reduce the
overall disk consumption from almost 300 GB to 15 GB, a 1/20. Some
repos shrank from GBs to below a MB.
Perhaps I should make all my git clones use one of the filters.
The initial dip from 100% to 95% is my first "what happens if we block repos
> 500 MB" attempt. Over the week after that, the git filter clones reduce the
overall disk consumption from almost 300 GB to 15 GB, a 1/20. Some
repos shrank from GBs to below a MB.
Perhaps I should make all my git clones use one of the filters.
 Last week we held our promised miniDebConf in Santa Fe City, Santa Fe province,
Argentina just across the river from Paran , where I have spent almost six
beautiful months I will never forget.
Last week we held our promised miniDebConf in Santa Fe City, Santa Fe province,
Argentina just across the river from Paran , where I have spent almost six
beautiful months I will never forget.




 Closing arguments in the trial between various people and
Closing arguments in the trial between various people and  Happy to share that
Happy to share that 